









堆疊的抽象資料結構
堆疊 (Stack) 是一種受到限制的線性 (Linear) 資料結構,其特性是只能由單一出入口進行資料的存取。
堆疊的核心存取原則為 FILO (First-In, Last-Out,先進後出)。讀者可以將堆疊想像成一個直立的長桶子:最先放入的物品會沉在桶子底部,而最後放入的物品則會疊在最上方。

一個堆疊 S 至少會具備以下四個核心操作:
IsEmpty(S):檢查堆疊是否為空,回傳布林值。Peek(S):檢視堆疊最上方的元素,且不改變堆疊大小。Push(S, data):將新元素推入堆疊頂端,堆疊大小加 1。Pop(S):移出並回傳堆疊最上方的元素,堆疊大小減 1。
此外,以下兩個操作則是選擇性(Optional)的:
IsFull(S):檢查堆疊是否已滿。Size(S):回傳目前堆疊中的元素總數。
堆疊的資料型態
在本篇實作中,我們採用單向鏈結串列來建構堆疊。以下是相關的資料結構宣告:
typedef struct stack_node_t stack_node_t;
struct stack_node_t {
int data;
stack_node_t *next;
};
typedef struct stack_t stack_t;
struct stack_t {
stack_node_t *top;
size_t size;
size_t capacity;
};設計考量
- 選擇單向鏈結:由於堆疊的操作(Push/Pop)都只在頂端(Top)進行,使用雙向鏈結串列(Doubly Linked List)並不會帶來額外的效能優勢,因此選擇單向鏈結節點即可。
- 結構分離設計:我們將「堆疊節點 (
stack_node_t)」與「堆疊封裝 (stack_t)」分開宣告。因為個別節點不需要記錄size與capacity,將兩者分離可以有效節省記憶體空間,並讓程式碼的職責更清晰。
堆疊的公開界面
以下是本實作所提供的公開界面:
void stack_new(stack_t *self, size_t capacity);
void stack_delete(stack_t *self);
BOOL stack_push(stack_t *self, int data);
int stack_pop(stack_t *self);
#define stack_is_empty(s) ((s)->size <= 0)
#define stack_is_full(s) ((s)->size >= (s)->capacity)
#define stack_peek(s) ((s)->top->data)巨集(Macro)的使用考量
為了追求效能,我們將邏輯簡單、不需宣告區域變數的行為(如檢查狀態、檢視頂端元素)實作為巨集。這樣做可以消除函式呼叫(Function Call)時產生的堆疊框架(Stack Frame)開銷。
相反地,若是邏輯較為複雜、包含多行實作或需要宣告內部變數的行為,則不建議寫成巨集,應維持一般的函式設計以確保程式碼的安全與可讀性。
堆疊的建構函式
堆疊的建構函式實作如下:
void stack_new(stack_t *self, size_t capacity)
{
self->top = NULL;
self->size = 0;
self->capacity = capacity;
}使用範例與記憶體配置說明
實際的使用方式如下:
stack_t stack;
stack_new(&stack, 10);記憶體優化考量:
在此設計中,stack 變數本身配置於系統記憶體堆疊(Stack Frame)上,我們不需要呼叫 malloc 來動態配置。
因為 stack_t 結構體本質上只是用來記錄狀態與指向首個節點的指標,其空間開銷極小,直接宣告為區域變數即可,既能免去動態記憶體配置的開銷,也能避免忘記釋放而導致的記憶體洩漏(Memory Leak)風險。
堆疊的解構函式
由於堆疊內部的節點是以鏈結串列的方式動態串接,當堆疊不再使用時,我們必須逐一釋放所有節點的記憶體。
為了安全地釋放節點,我們需要用到兩個輔助指標:curr(當前節點)和 temp(暫存節點)。curr 一開始會指向堆疊的頂端(top),整個釋放流程如下:
記憶體釋放步驟圖解
-
暫存當前節點:先將
temp指向curr所指向的同一個節點。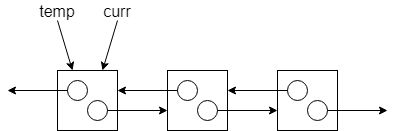
-
移動指標並釋放:將
curr移至下一個節點(curr->next),此時便可以安全地呼叫free(temp)將暫存的節點記憶體釋放掉。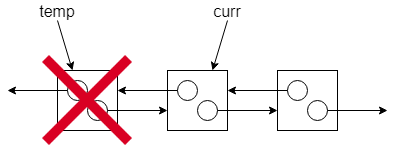
重複上述動作,直到 curr 變為 NULL 迴圈便會自動終止,如此就能將所有的內部節點完全釋放。
實作程式碼
參考以下完整的解構函式實作:
void stack_delete(stack_t *self)
{
stack_node_t *curr = NULL;
stack_node_t *temp = NULL;
curr = self->top;
while (curr) {
temp = curr;
curr = curr->next;
free(temp);
}
self->top = NULL;
self->size = 0;
}檢查堆疊是否為空
檢查堆疊是否為空非常簡單,只需要判斷內部記錄的 size 即可:
#define stack_is_empty(s) ((s)->size <= 0)⚠️ 注意事項:
由於此巨集完全依賴 size 的數值,因此在實作資料的推入(Push)與彈出(Pop)操作時,務必同步更新 size 的值,否則此判斷式將會失效。
檢視堆疊頂端的資料但不取出
檢視頂端元素的操作(Peek)非常直接,只需存取首個節點的資料:
#define stack_peek(s) ((s)->top->data)設計考量與防禦性程式設計
在這個巨集中,我們不進行堆疊是否為空的檢查。主要原因如下:
- 效能優化:不重複做多餘的檢查,維持巨集的高效能。
- 責任分離:我們已經提供了
stack_is_empty巨集。在 C 語言的設計慣例中,函式庫呼叫者有責任在調用stack_peek前,先確認堆疊是否為空。若強行存取空堆疊的top->data將導致記憶體區段錯誤(Segmentation Fault)。
將資料推入堆疊
將新資料推入堆疊(Push)的指標操作主要分為兩個步驟:
-
建立並串接新節點:配置一個新的資料節點,並將該節點的
next指向目前top所指向的節點。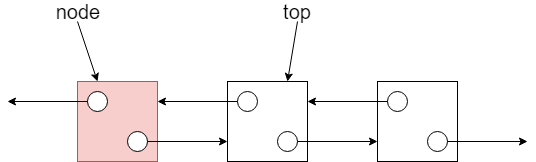
-
更新頂端指標:將
top重新指向這個新建立的節點。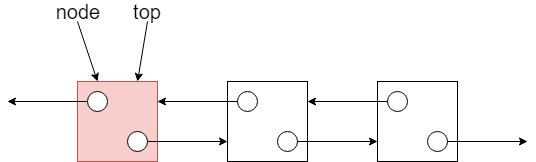
內部輔助函式:建立新節點
為了提高程式碼的重用性,並避免每次新增節點時重複撰寫相同的邏輯,我們抽離出一個內部的輔助函式:
static stack_node_t * stack_node_new(int data)
{
stack_node_t *node = malloc(sizeof(stack_node_t));
if (!node) return NULL;
node->data = data;
node->next = NULL;
return node;
}實作程式碼
以下是完整的 stack_push 函式實作:
BOOL stack_push(stack_t *self, int data)
{
stack_node_t *node = stack_node_new(data);
if (!node) return FALSE;
node->next = self->top;
self->top = node;
self->size++;
return TRUE;
}設計考量
- 錯誤處理機制:由於建立節點時涉及動態記憶體配置(
malloc),有可能會因為系統記憶體不足而失敗。因此,我們的公開界面會回傳一個布林值(BOOL),讓呼叫者知道操作是否成功。 - 邊界條件通用性:不論目前的
top是NULL(空堆疊)還是已經有其他節點存在,這段程式碼的邏輯都能完美適用。讀者可以嘗試在腦中或是紙上追蹤(Trace)看看,即可理解其通用性。
將資料從堆疊彈出
為了將資料移出堆疊(Pop),我們需要使用一個輔助指標 curr 來暫存即將被刪除的節點。操作步驟如下:
-
暫存頂端節點:一開始先將
curr指向目前top所在的頂端節點,並取出其中的資料。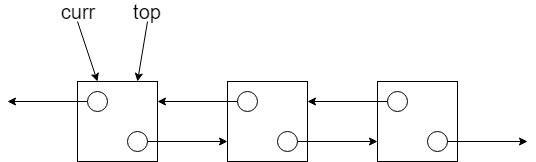
-
更新頂端並釋放:將
top移向新頂端(下一個節點curr->next)之後,便可以安全地呼叫free(curr)將原來的節點記憶體釋放。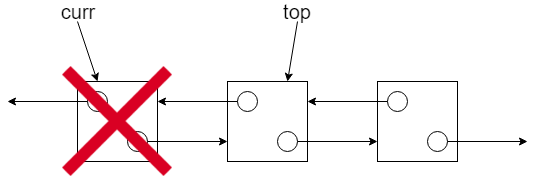
邊界條件考量
如果堆疊中只有一個節點呢?同樣的步驟依然成立。因為當 top 移向下一個節點時,會剛好承接該節點的 next 值(即 NULL),整個操作依然安全且符合預期。
實作程式碼
以下是完整的 stack_pop 函式實作:
int stack_pop(stack_t *self)
{
stack_node_t *curr = NULL;
int data = 0;
curr = self->top;
data = curr->data;
self->top = curr->next;
free(curr);
self->size--;
return data;
}設計前提
延續前面的設計哲學,本函式是建立在堆疊不為空的假設上。函式庫的使用者必須自行調用 stack_is_empty 排除堆疊為空的情形。只要確保堆疊有資料,這段程式碼不論在一般狀況或只剩單一節點的邊界狀況下都能完美運作,讀者可以自行追蹤程式碼來驗證。
在演算法上的效率
根據本篇以鏈結串列為基礎的實作,各項操作的時間複雜度如下:
IsEmpty:O(1)Peek:O(1)Push:O(1)Pop:O(1)
理論與實務的差異說明
在學術考試或演算法分析中,通常會將記憶體動態配置與釋放(即 malloc 和 free 函式)的效率視為 O(1),因此 Push 和 Pop 的時間複雜度在理論上皆為 O(1)。
然而在實際的作業系統與工程環境中,malloc 和 free 的底層實作取決於記憶體分配器(Memory Allocator,如 glibc 的 ptmalloc、jemalloc 等)。它們需要尋找合適的記憶體區塊、處理記憶體碎片,有時甚至需要透過系統呼叫(System Call)向作業系統要求更多記憶體,因此實際的執行時間會有所波動。