









前言
文字處理是電腦程式中經常會遇到的情境。字串是在記憶體中儲存文字資料的一種資料型態。本文將說明如何在 C 語言中處理字串。
C 語言實作
C 語言沒有獨立的字串型別。所謂的 C 字串,其實是以 char 或其他字元 (character) 為基礎型態的陣列。因此,C 字串的各種運算,本質上就是對字元陣列的一系列操作。
處理多國語系文字
在 C 語言中,常見的字串處理方式大致有以下幾種:
- 固定寬度字元陣列
- 字元陣列 (character array)\
- 寬字元陣列 (wide character array):使用 wchar.h 函式庫
- 多字節編碼 (multibyte encodings),例如 Big5(大五碼)或 GB2312 等
- 統一碼 (Unicode):包括 UTF-8、UTF-16、UTF-32 等
有些方案採用等寬字元,有些則採用不等寬字元編碼。最原始的字元陣列主要用於處理英文文字,而其他方案則是為了支援多國語系文字而產生。
例如,在支援 Unicode 的終端機環境中,可以透過 wchar_t 印出中文字串:
#include <locale.h>
#include <stdio.h>
#include <wchar.h>
int main(void)
{
/* Enable locale for multibyte output. */
setlocale(LC_CTYPE, "");
wchar_t *s = L"你好,世界";
printf("%ls\n", s);
return 0;
}由於本文的目的是了解字串的基本操作,因此後續內容仍以最基本的字元陣列為主,不考慮多國語系的情境。
C 字串微觀
我們以 "Hello World" 這個字串來觀察 C 字串的組成。
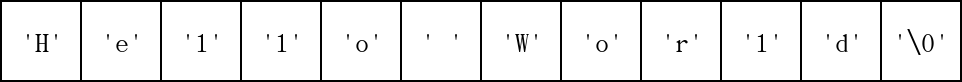
由上圖可以看到,C 字串除了依序儲存每個字元外,在尾端還會額外加入一個 \0 字元,作為字串結束的標記。
由於 C 字串需要依靠尾端的 \0 來判斷字串結束,因此在處理字串時,務必要記得在字串尾端加入此字元。
接下來,我們會介紹幾種常見的字串操作情境。C 標準函式庫已經提供了 string.h,在實務上應優先使用這些現成函式,而不是自行重造輪子;本文的程式碼僅作為理解字串運作原理的示範。
計算 C 字串長度
計算字串長度時,不包含尾端的結束字元。因此,C 字串 "happy" 的長度為 5,而不是 6。
#include <assert.h>
#include <stddef.h>
#include <string.h>
int main(void)
{
char s[] = "Hello";
size_t sz = 0;
for (size_t i = 0; s[i]; i++) {
sz++;
}
assert(sz == strlen(s));
return 0;
}我們透過走訪字串來計算字串長度。當字串走訪到尾端的零值時,s[i] 會回傳零,迴圈便會結束。
複製 C 字串
一般 strcpy 的範例通常會先配置固定長度的字元陣列。本例稍作修改:先動態計算來源字串的長度,再於堆積 (heap) 上配置新的字元陣列,最後將原字串逐一複製到目標字串中。
#include <assert.h> /* 1 */
#include <stddef.h> /* 2 */
#include <stdio.h> /* 3 */
#include <stdlib.h> /* 4 */
#include <string.h> /* 5 */
int main(void) /* 6 */
{ /* 7 */
char s[] = "Hello World"; /* 8 */
size_t sz_s = strlen(s); /* 9 */
size_t sz = sz_s + 1; /* Add trailing zero. */ /* 10 */
char *out = malloc(sz * sizeof(char)); /* 11 */
if (!out) { /* 12 */
fprintf(stderr, "Failed to allocate C string\n"); /* 13 */
return 1; /* 14 */
} /* 15 */
for (size_t i = 0; i < sz_s; i++) { /* 16 */
out[i] = s[i]; /* 17 */
} /* 18 */
out[sz-1] = '\0'; /* 19 */
assert(0 == strcmp(out, "Hello World")); /* 20 */
free(out); /* 21 */
return 0; /* 22 */
} /* 23 */要配置記憶體前,要先知道記憶體的長度,所以我們在第 10 行計算字串的長度。
接著,我們在第 11 行為字串配置記憶體。
拷貝字串的方式為逐一拷貝字元陣列內的字元,該動作位於第 16 行至第 18 行。
此外,還要為字元加上尾端的零值,該動作為於第 19 行。
在本例中,由於 out 是由 heap 配置記憶體,使用完要記得手動釋放,該動作位於第 21 行。
相接兩個 C 字串
原本的 strcat 函式需要事先估計目標字串的長度。本例先計算兩個字串的長度,再配置新的字元陣列並依序複製。
#include <assert.h> /* 1 */
#include <stdio.h> /* 2 */
#include <stdlib.h> /* 3 */
#include <string.h> /* 4 */
int main(void) { /* 5 */
char s_a[] = "Hello "; /* 6 */
char s_b[] = "World"; /* 7 */
size_t sz_a = strlen(s_a); /* 8 */
size_t sz_b = strlen(s_b); /* 9 */
size_t sz = sz_a + sz_b + 1; /* 10 */
char *out = malloc(sz * sizeof(char)); /* 11 */
if (!out) { /* 12 */
fprintf(stderr, /* 13 */
"Failed to allocate C string\n"); /* 14 */
return 1; /* 15 */
} /* 16 */
for (size_t i = 0; i < sz_a; i++) { /* 17 */
out[i] = s_a[i]; /* 18 */
} /* 19 */
for (size_t i = 0; i < sz_b; i++) { /* 20 */
out[i+sz_a] = s_b[i]; /* 21 */
} /* 22 */
out[sz-1] = '\0'; /* 23 */
assert(strcmp(out, "Hello World") == 0); /* 24 */
free(out); /* 25 */
return 0; /* 26 */
} /* 27 */如同上一節的例子,我們要先計算記憶體的長度,所以我們在第 10 行計算字串長度,並預先加入尾端零值的長度。
本例有兩段字串,所以拷貝字串的動作要分兩輪。在第 17 行至第 19 行間拷貝第一個字串。在第 20 行至 22 行間拷貝第二個字串。
別忘了加上尾端零值,這段動作發生在第 23 行。
在本例中,由於 out 是由 heap 配置記憶體,使用完要記得手動釋放。本動作在第 25 行完成。
檢查兩個 C 字串是否相等
檢查字串相等的方式為逐一檢查字元陣列的字元是否相等。可參考以下範例程式碼:
#include <assert.h> /* 1 */
#include <stdbool.h> /* 2 */
int main(void) /* 3 */
{ /* 4 */
char a[] = "happy"; /* 5 */
char b[] = "happy hour"; /* 6 */
bool is_equal = true; /* 7 */
char *p = a; /* 8 */
char *q = b; /* 9 */
while (*p && *q) { /* 10 */
/* Unequal character. */ /* 11 */
if (*p != *q) { /* 12 */
is_equal = false; /* 13 */
goto END; /* 14 */
} /* 15 */
p++; q++; /* 16 */
} /* 17 */
/* Unequal string length. */ /* 18 */
if (*p != *q) { /* 19 */
is_equal = false; /* 20 */
goto END; /* 21 */
} /* 22 */
END: /* 23 */
assert(false == is_equal); /* 24 */
return 0; /* 25 */
} /* 26 */我們不希望影響原本的字元陣列,所以我們在第 8 行及第 9 行分別拷貝兩字元陣列的位址。
檢查字元陣列的動作位於第 10 行至第 17 行。當字元不相等時,直接結束比較字元陣列的迴圈。
兩字元有可能部分相等,但兩者不等長。所以我們在第 19 行至第 21 行檢查兩字元陣列的尾端是否相等。
在這裡我們不直接檢查字串長度,因為這樣會多走訪一輪字串。我們先逐一檢查字元是否相等,在尾段則檢查兩字串長度是否相等。
尋找子字串
尋找子字串的示意圖如下:

本命題的想法相當簡單,我們逐一走訪原字串,在每個位置檢查是否符合子字串。以下是參考實作:
#include <assert.h> /* 1 */
#include <stdbool.h> /* 2 */
int main(void) /* 3 */
{ /* 4 */
/* Original string. */ /* 5 */
char s[] = "The quick brown fox jumps over the lazy dog"; /* 6 */
/* Substring. */ /* 7 */
char ss[] = "lazy"; /* 8 */
bool is_found = false; /* 9 */
char *p = s; /* 10 */
while (*p) { /* 11 */
bool temp = true; /* 12 */
char *q = p; /* 13 */
char *r = ss; /* 14 */
while (*q && *r) { /* 15 */
if (*q != *r) { /* 16 */
temp = false; /* 17 */
break; /* 18 */
} /* 19 */
q++; r++; /* 20 */
} /* 21 */
if (!(*r)) { /* 22 */
is_found = true; /* 23 */
break; /* 24 */
} /* 25 */
p++; /* 26 */
} /* 27 */
assert(is_found); /* 28 */
return 0; /* 29 */
} /* 30 */走訪原字串的迴圈位於第 11 行至第 27 行。在走訪時,我們在每個位置逐一比較子字串是否相符。比較子字串的迴圈位於第 15 行至第 21 行。
要注意每次走訪子字串時,都要重新拷貝字串的位址,才可以重覆走訪。
結語
在本文中,我們學習了幾個與字串相關的基本演算法。學習這些演算法的目的並不是要取代標準函式庫中的字串函式,而是讓我們在沒有現成函式可用時,仍然有能力自行實作所需的字串處理函式。